🐍 정규표현식이란
정규표현식은 문자열이 특정 패턴과 일치하는지 판단하는 형식 언어이다.
regular expression의 약자인 regex라고도 함.
사용예시
- 사용자가 입력한 이메일이 유효한 이메일인지,
- 유효한 핸드폰 번호를 입력했는지,
- 대문자로 시작하고 숫자로 끝나는 패턴의 단어가 몇번 반복되는지 등
- 다양한 패턴을 지정하고 검증할 수 있음.
정규표현식을 사용하지 않은 코드
정규표현식을 사용한 코드
두 가지의 차이를
예제를 통해 비교해보자
🐍 예제 : 이메일 형식 검증
유효한 이메일인지 판단하는 최소한의 패턴은 다음과 같다.
- 숫자, 알파벳 대/소문자, 일부 특수문자( - _ . )를 조합한 문자로 시작함
- 문자열 중간에는 @가 반드시 1개 포함되어 있어야 함
- @ 이후에는 숫자, 알파벳 대/소문자, 일부 특수문자( - _ . )를 조합한 문자가 들어감
- 3번 문자 이후에는 .이 한 개 이상 포함되어 있어야 함
- 마지막 . 이후에는 2 ~ 4글자의 숫자, 알파벳 대/소문자, 일부 특수문자( - _ )를 조합한 문자 포함되어 있어야 함
🐍 정규표현식 없이 위 조건들을 만족하기 위한 코드
from pprint import pprint
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
number = "0123456789"
special_char = "-_."
def verify_email(email):
# 이메일에 @가 한개 포함되어 있는지 확인
if email.count("@") != 1:
return False
# @를 기준으로 사용자명과 도메인을 분리
username, domain = email.split("@")
# username이 1자 이상인지 확인
if len(username) < 1:
return False
# 도메인에 한개 이상의 .이 포함되어 있는지 확인
if domain.count(".") < 1:
return False
# username에 알파벳, 숫자, 허용된 특수문자 이외의 문자가 포함되어 있는지 확인
if not all([x in alphabet + number + special_char for x in username]):
return False
# domain에 알파벳, 숫자, 허용된 특수문자 이외의 문자가 포함되어 있는지 확인
if not all([x in alphabet + number + special_char for x in domain]):
return False
# 마지막 .을 기준으로 도메인을 분리
_, last_level_domain = domain.rsplit(".", 1)
# 마지막 레벨의 도메인의 길이가 2~4글자인지 확인
if not 2 <= len(last_level_domain) <= 4:
return False
# 모든 검증이 완료되면 True를 리턴
return True
🐍 정규표현식을 사용한 코드
from pprint import pprint
import re
# rstring : backslash(\)를 문자 그대로 표현
# ^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$ : 이메일 검증을 위한 정규표현식 코드
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")
def verify_email(email):
return bool(email_regex.fullmatch(email))
후자의 코드가 훨씬 간결하고, 결과는 똑같다
test_case = [
"apple", # False
"sparta@regex", # False
"$parta@regex.com", # False
"sparta@re&ex.com", # False
"spar_-ta@regex.com", # True
"sparta@regex.co.kr", # True
"sparta@regex.c", # False
"sparta@regex.cooom", # False
"@regex.com", # False
]
result = [{x: verify_email(x)} for x in test_case]
pprint(result)
🐍 정규표현식 코드를 짜는 방법
위 예제에서 사용한 정규표현식 코드 부분만 다시 확인해 보면,
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")머라는건지 모르겠고 이걸 외울 순 없을 것 같다.
이처럼 정규표현식으로 내가 원하는 패턴의 코드를 직접 짜는 것은 매우 어렵기 때문에
이미 만들어져 있고 검증 된 정규표현식을 가져다가 사용하는 것이 권장된다.
위 예제와 같이 이메일 검증, 패스워드 안정성 검증, 핸드폰번호 검증과 같이 대중적으로 많이 사용되는 정규표현식 코드들은 구글에서 검색 해 보면 쉽게 찾아볼 수 있다.

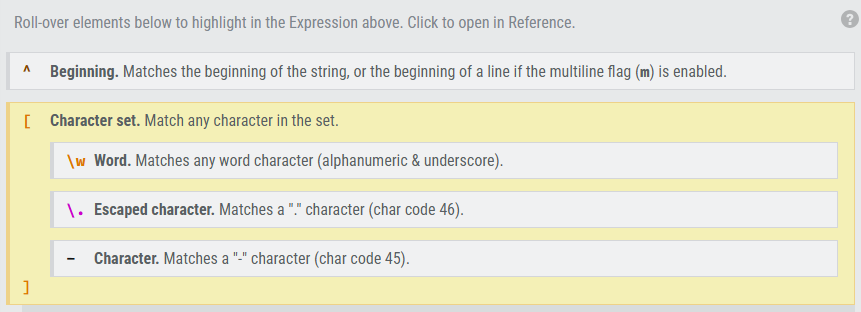
반대로 다른 사람이 작성한 코드 중에서 알수 없는 정규표현식 코드가 있다면,
아래의 사이트에 복붙으로 넣어주면
해당 정규표현식 문법에 대한 설명을 자세하게 확인할 수 있다.
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com



🐍 주의해야할 점
언어마다 정규식을 다루는 방법이 조금씩 다를 수 있다.
따라서, 정규식 사이트에서는 잘 동작하던 코드가 내 로컬에서 안돌아간다?
그러면 구글에 Python password validation regex 이런식의 키워드로 검색해서 찾아보자.
마지막으로
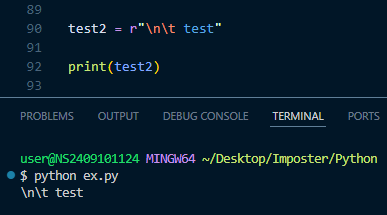
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")regex 문자열 앞에 있는 r 의 의미는
정규표현식에서 특정한 문자들을 특수문자로 인식하는 것을 방지하기 위함이다.
무슨말이냐면
파이썬 문자열에서 역슬래시 \ 뒤에 오는 문자는 특수문자 의미를 갖고 있는데,
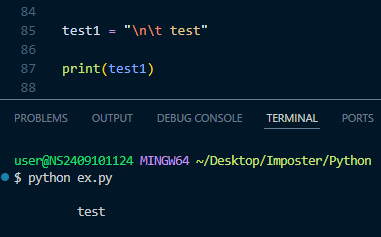
\n # 개행을 의미함
\t # Tab 을 의미함
이 때 앞에 r을 붙여주면 역슬래시 다음의 문자들을 특수 문자가 아니라
온전히 그 문자 그대로를 의미할 수 있게 해준다.