배열(Array) / 연결리스트(Linked list)
| 배열 | 연결리스트 | |
| 크기 | 고정 | 동적 |
| 주소 | 연속 | 불연속 |
| 데이터 검색(참조) | O(1) | O(n) |
| 데이터 추가/삭제 | O(n) | O(1) |
배열 (Array)
: 같은 타입의 변수들로 이루어진 집합으로, 연속공간에 값이 채워져 있는 형태.

'A', 'B', 'C', 'D', 'E' 라는 데이터가 있다. 이 데이터들을 배열로 저장해볼거다

먼저 연속적으로 붙어있는 상자를 구해준다. 데이터가 5개니까 상자도 5칸
(= 배열은 선언할 때 크기가 미리 지정된다)

각 상자(데이터가 들어갈 주소)들에는 차례대로 번호가 부여되는데, 이 번호를 '인덱스' 라고 한다.

0부터 시작하기 때문에 인덱스는 초기값을 기준으로 주소가 떨어진 거리에 해당한다.
ex) 첫번째 데이터는 인덱스 0, 두번째 데이터는 인덱스 1

첫번째 데이터부터 각 상자에 차례대로 집어 넣어주면 배열 끝
순서에 맞게 들어갔기 때문에, 각 데이터를 방문할 때는 해당 데이터가 들어간 주소에 할당된 인덱스를 사용해 찾을 수 있다.

그래서 만약 내가 찾고싶은 요소 'DI'가 5000번째에 있더라도 인덱스[5000] 으로 한번에 찾아낼 수 있다.
따라서 배열은 '데이터 검색'에 있어서 O(1)의 시간복잡도를 가진다.

근데 만약 'X' 라는 변수를 첫번째에 넣고싶다면
상자에 들어있는 변수들이 모 뒤로 한칸씩 이동해줘야한다...
마찬가지로 중간에 있는 'C'를 삭제하려면, 'C' 이후의 변수들은 모두 앞으로 한칸씩 옮겨와야된다. 데이터 한개만 바꿀려는데 N개의 이동을 발생시킨다.
따라서 배열은 '데이터 추가/삭제'에 있어서 O(N)의 시간복잡도를 가진다.

배열의 메모리 공간 활용은 비효율적이다.
만약 메모리공간에 이미 공간을 사용중인 데이터들이 있고 5크기의 배열을 저장해야 한다면 5연속 공간을 찾아서 집어넣어야 하기 때문에

작은 공간들은 쓰레기가 될 수 있다ㅜ
연결리스트 (Linked List)
: 배열의 단점을 보완하기 위해 만들어짐. 데이터를 분산해서 저장하고, 연결해준다.

연결리스트는 한줄로 연결된 노드들의 집합이다.
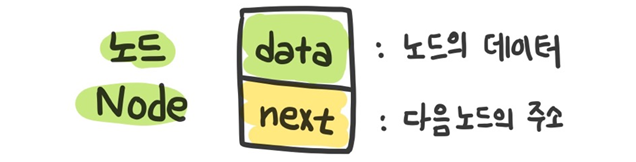
노드를 확대해보면 두개의 필드를 갖고있다. 데이터를 저장하는 data 필드와 다음노드의 주소를 가리키는 next 필드이다.

첫 시작 노드는 head node라고 한다.
첫번째 노드의 data 필드에는 'A'가 저장되어 있고 next 필드는 'B' 노드를 가리킨다. 이런식으로 계속 연결이 진행되고, 맨 마지막 노드의 next 필드는 Null 을 가리킨다.

그래서 만약 'DI' 라는 데이터를 찾고싶다면, head 부터 시작해서 계속 next를 타고 순회해서 'DI'가 있는 노드까지 도달해야한다. 노드의 위치는 바로 그 전 노드만이 알고 있기 때문에, 한개의 데이터를 찾는데도 N개의 이동을 거쳐간다.
따라서 연결리스트는 '데이터 검색'에 있어서 O(N)의 시간복잡도를 가진다.

반대로 데이터를 수정하는 건 쉽다.
'X' 라는 데이터를 'A' 와 'B' 사이에 추가하려면 A-B 사이의 링크를 끊어버리고 'X'에게 링크를 새로 연결해주면 된다.
마찬가지로 'B' 데이터를 삭제하려면 'B' 노드를 없애버리고 'B' 이전 노드의 next가 가리키는 위치만 새로 지정해주면 된다.
따라서 연결리스트는 '데이터 추가/삭제'에 있어서 O(1)의 시간복잡도를 가진다.

연결리스트는 선언할 때 크기를 지정하지 않고 연속된 공간을 필요로 하지 않기 때문에, 메모리 공간에 미리 저장되어있는 데이터가 있어도 빈 공간을 활용할 수 있다.

이렇게 요소들을 분산해서 저장하고 이어주면 되기 때문에 공간 효율적이다.
'알고리즘&자료구조' 카테고리의 다른 글
| [알고리즘] 중첩 for문 문제 (0) | 2024.07.22 |
|---|---|
| [알고리즘] 버블 정렬(Bubble Sort) (0) | 2024.07.19 |
| [자료구조] Linked List 클래스 정의 (0) | 2024.07.18 |
| [자료구조] 스택 Stack (0) | 2024.07.17 |
| [자료구조] 스택 - 키보드 Backspace / 괄호문법검사기 (0) | 2024.07.16 |